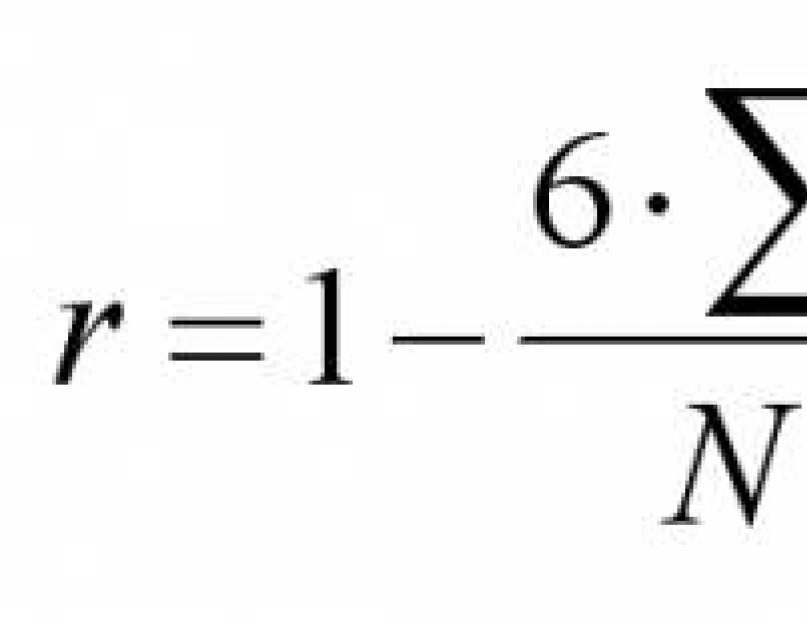
37. Spearman-féle rangkorrelációs együttható.
S. 56 (64) 063.JPG
http://psystat.at.ua/publ/1-1-0-33
A Spearman-féle rangkorrelációs együtthatót akkor használjuk, ha:
- a változóknak van rangsor skála mérések;
- az adatelosztás túlságosan eltér a Normál vagy egyáltalán nem ismert
- a minták kicsik (N< 30).
A Spearman-féle rangkorrelációs együttható értelmezése nem különbözik a Pearson-féle együtthatótól, de jelentése némileg eltér. Ahhoz, hogy megértsük e módszerek közötti különbséget és logikusan alá tudjuk támasztani alkalmazási területeiket, hasonlítsuk össze képleteiket.
Pearson korrelációs együttható:
Spearman-féle korrelációs együttható: 
Mint látható, a képletek jelentősen eltérnek egymástól. Hasonlítsa össze a képleteket
A Pearson-féle korrelációs képlet a korrelált sorozatok számtani átlagát és szórását használja, míg a Spearman-képlet nem. Tehát ahhoz, hogy a Pearson-képlet szerint megfelelő eredményt kapjunk, szükséges, hogy a korrelált sorozatok közel álljanak a normális eloszláshoz (az átlag és a szórás normál eloszlási paraméterek). A Spearman-képlet esetében ez nem releváns.
A Pearson-képlet egyik eleme az egyes sorozatok szabványosítása z-pontszám.

Amint látható, a változók Z-skálára való átalakítása a Pearson-féle korrelációs együttható képletében található. Ennek megfelelően a Pearson-együttható esetében az adatok skálája abszolút nem releváns: például két változót korrelálhatunk, amelyek közül az egyiknek min. = 0 és max. = 1, és a második min. = 100 és max. = 1000. Függetlenül attól, hogy az értékek tartománya mennyire eltérő, mindegyiket átváltja szabványos z-értékekre, amelyek skálája megegyezik.
A Spearman-együtthatóban nincs ilyen normalizálás, tehát
A SPEERMAN-EGYÜTTŐ HASZNÁLATÁNAK KÖTELEZŐ FELTÉTELE KÉT VÁLTOZÓ TARTOMÁNYÁNAK EGYENLŐSÉGE.
Mielőtt a Spearman-együtthatót különböző tartományú adatsorokhoz használná, szükséges rang. A rangsorolás azt a tényt eredményezi, hogy ezen sorozatok értékei ugyanazt a minimumot = 1-et (minimum rang) és az értékek számával megegyező maximumot kapnak (maximum, utolsó rang = N, azaz az esetek maximális száma a rendszerben). minta).
Milyen esetekben lehetséges rangsorolás nélkül
Ezek olyan esetek, amikor az adatok eredetiek rangsor skála. Például a Rokeach értékorientációs teszt.
Ezek olyan esetek is, amikor az értékopciók száma kicsi, és a mintában rögzített minimum és maximum van. Például a szemantikai differenciálban minimum = 1, maximum = 7.
Példa a Spearman-féle rangkorrelációs együttható kiszámítására
A Rokeach értékorientációs tesztet két X és Y mintán végeztük el. A feladat az volt, hogy megtudjuk, mennyire közel állnak ezeknek a mintáknak az értékhierarchiái (szó szerint mennyire hasonlóak).

A kapott r=0,747 értéket összevetjük kritikus érték táblázat. A táblázat szerint N=18-nál a kapott érték p szinten megbízható<=0,005
Rangkorrelációs együtthatók Spearman és Kendal szerint
Az ordinális skálához tartozó, illetve a normál eloszlást nem követő változók, valamint az intervallumskálához tartozó változók esetében a Pearson-együttható helyett Spearman-féle rangkorrelációt számolunk. Ehhez a változók egyedi értékei rangsorolási helyeket kapnak, amelyeket ezt követően a megfelelő képletek segítségével dolgoznak fel. A rangkorreláció felfedéséhez törölje a jelet az alapértelmezett Pearson-korreláció jelölőnégyzetből a Bivariate Correlations... párbeszédpanelen. Ehelyett aktiválja a Spearman-korrelációs számítást. Ez a számítás a következő eredményeket adja. A rangkorrelációs együtthatók nagyon közel állnak a Pearson-együtthatók megfelelő értékéhez (az eredeti változók normális eloszlásúak).
titkova-matmetody.pdf p. 45
A Spearman-féle rangkorrelációs módszer lehetővé teszi a szorosság (erősség) és az irány meghatározását
közötti korreláció két jel vagy két profil (hierarchia) jelek.
A rangkorreláció kiszámításához két értéksorra van szükség,
amelyek rangsorolhatók. Ezek az értéktartományok a következők lehetnek:
1) két jel ugyanabban mérve csoport tesztalanyok;
2) két egyedi jellemző hierarchia, két alanyban azonosították ugyanarra
funkciók halmaza;
3) kettő jellemzők csoportos hierarchiája,
4) egyéni és csoportos jellemzői hierarchia.
Először is, a mutatók külön-külön vannak rangsorolva az egyes funkciókhoz.
Általános szabály, hogy egy jellemző alacsonyabb értéke alacsonyabb rangot kap.
Az első esetben (két jellemző) az egyedi értékek az első szerint vannak rangsorolva
a különböző alanyok által szerzett tulajdonság, majd a második egyéni értékei
jel.
Ha két jel pozitív kapcsolatban áll, akkor az alacsony rangú alanyok kerülnek be
egyikük alacsony besorolású lesz a másikban, a magas rangú alanyok pedig be
az egyik tulajdonság a másik tulajdonságon is magas rangot kap. rs számolásához
meg kell határozni a különbségeket d) ezen alanyok által mindkettőn szerzett rangok között
jelek. Ezután ezeket a d mutatókat egy bizonyos módon átalakítjuk, és kivonjuk 1-ből
minél kisebb a különbség a rangok között, annál nagyobb lesz az rs, annál közelebb lesz a +1-hez.
Ha nincs összefüggés, akkor minden rang vegyes lesz, és nem lesz
nem egyezik. A képlet úgy van megtervezve, hogy ebben az esetben rs közel legyen a 0-hoz.
Negatív korreláció esetén az alanyok alacsony rangja egy alapon
egy másik attribútumban magas rangoknak felel meg, és fordítva. Minél több az eltérés
az alanyok rangsorai között két változóban az rs közelebb van -1-hez.
A második esetben (két egyéni profil), Egyedi
a két alany mindegyike által meghatározott értékek szerint (ugyanaz nekik
mindkettő) jellemzők halmaza. Az első rangú a legalacsonyabb értékű tulajdonságot kapja; második fokozat -
nagyobb értékű jel stb. Nyilvánvalóan minden tulajdonságot bele kell mérni
ugyanazok az egységek, különben lehetetlen a rangsorolás. Például lehetetlen
rangsorolja a mutatókat a Cattell személyiségkérdőív (16PF) szerint, ha kifejezve vannak
"nyers" pontszámok, mivel az értéktartományok különböző tényezők esetén eltérőek: 0-tól 13-ig, 0-ig
20 és 0-tól 26-ig. Nem tudjuk megmondani, hogy a tényezők közül melyik kerül az első helyre
súlyosság, amíg az összes értéket egyetlen skálára nem hozzuk (leggyakrabban ez a falak skálája).
Ha két tantárgy egyéni hierarchiája pozitív kapcsolatban áll egymással, akkor a jelek
ha az egyikben alacsony a beosztás, akkor a másikban is alacsonyak lesznek, és fordítva.
Például, ha egy alany esetében az E faktor (dominancia) a legalacsonyabb rangú, akkor az esetében
egy másik alanynak alacsony rangúnak kell lennie, ha az egyik alany rendelkezik C faktorral
(érzelmi stabilitás) rendelkezik a legmagasabb ranggal, akkor a másik alanynak is rendelkeznie kell
ennek a tényezőnek magas a rangja stb.
A harmadik esetben (két csoportprofil) az átlagos csoportértékeket rangsoroljuk,
2 alanycsoportban kapott egy bizonyos, két csoportra azonos, halmazra
jelek. A következőkben a gondolatmenet ugyanaz, mint az előző két esetben.
A 4. (egyéni és csoportos profil) esetén külön rangsorolják
az alany egyéni értékei és az átlagos csoportértékek ugyanahhoz a halmazhoz
jelek, amelyeket általában, ennek az egyéni alanynak a kizárásával szereznek - ő
nem vesz részt az átlagos csoportprofilban, amellyel az egyént összehasonlítják
profil. A rangkorreláció lehetővé teszi annak ellenőrzését, hogy mennyire konzisztens az egyén és
csoportprofilok.
A kapott korrelációs együttható szignifikanciáját mind a négy esetben az határozza meg
a rangsorolt értékek száma szerint N. Az első esetben ez a szám egybe fog esni
mintanagyság n. A második esetben a megfigyelések száma a jellemzők száma lesz,
hierarchiát alkotnak. A harmadik és negyedik esetben N az egyezések száma is
jelek, nem a csoportokban lévő alanyok száma. A részletes magyarázatok a példákban találhatók. Ha egy
rs abszolút értéke elér egy kritikus értéket, vagy meghaladja azt, a korreláció
megbízható.
Hipotézisek.
Két hipotézis lehetséges. Az első az 1. esetre vonatkozik, a második a másik háromra
A hipotézisek első változata
H0: Az A és B változók közötti korreláció nem különbözik nullától.
H2: Az A és B változók közötti korreláció szignifikánsan különbözik a nullától.
A hipotézisek második változata
H0: Az A és B hierarchia közötti korreláció nem különbözik a nullától.
H2: Az A és B hierarchia közötti korreláció jelentősen eltér a nullától.
A rangkorrelációs együttható korlátai
1. Változónként legalább 5 észrevételt kell benyújtani. Felső
a mintavételi határértéket a rendelkezésre álló kritikus értékek táblázatai határozzák meg .
2. A Spearman-féle rangkorrelációs együttható rs nagy számú azonos értékkel
Az egyik vagy mindkét egyeztetett változó rangsorolása durva értékeket ad. Ideális esetben
mindkét korrelált sorozatnak két nem egyező sorozatnak kell lennie
értékeket. Ha ez a feltétel nem teljesül, ki kell igazítani
ugyanazok a rangok.
A Spearman-féle rangkorrelációs együttható a következő képlettel számítható ki:

Ha mindkét összehasonlított rangsorban vannak azonos rangú csoportok,
a rangkorrelációs együttható kiszámítása előtt ugyanerre korrigálni kell
rangsorolja a Ta-t és a Tv-t:
Ta \u003d Σ (a3 - a) / 12,
TV \u003d Σ (v3 - c) / 12,
ahol a - az A rangsor minden azonos rangú csoportjának volumene, in – mindegyik kötete
egyenlő rangú csoportok a B rangsorban.
Az rs tapasztalati értékének kiszámításához használja a következő képletet:

38. Pontozott biserial korrelációs együttható.
A korrelációról általában lásd a 36. kérdést Val vel. 56 (64) 063.JPG
harchenko-korranaliz.pdf
Mérjük az X változót erős skálán, az Y változót pedig egy dichotóm skálán. Az rpb pontbiserial korrelációs együttható a következő képlettel számítható ki:

Itt x 1 X objektum átlagos értéke, Y esetén "egy";
x 0 - az átlagos érték X objektumhoz, Y "nulla" értékével;
s x - az X összes értékének szórása;
n 1 - az objektumok száma "egy" Y-ben, n 0 - az objektumok száma "nulla" Y-ban;
n = n 1 + n 0 a minta mérete.
A pontbisoros korrelációs együttható más ekvivalens kifejezésekkel is kiszámítható:


Itt x a változó általános átlagértéke x.
Pont biserial korrelációs együttható rpb-1 és +1 között változik. Értéke nullával egyenlő abban az esetben, ha a változók egysége for Yátlaga legyen Y, egyenlő a nulla feletti változók átlagával Y.
Vizsgálat szignifikancia hipotézisek pont biserial korrelációs együttható ellenőrzése null hipotézisth 0 az általános korrelációs együttható nullával való egyenlőségéről: ρ = 0, amelyet a Student-féle kritérium alapján hajtunk végre. Empirikus érték

kritikus értékekkel összehasonlítva t a (df) a szabadságfokok számához df = n– 2
Ha a feltétel | t| ≤ ta(df), a ρ = 0 nullhipotézist nem utasítják el. A pontbiserial korrelációs együttható szignifikánsan eltér a nullától, ha a tapasztalati érték | t| a kritikus tartományba esik, vagyis ha a | t| > ta(n– 2). A pontbiserial korrelációs együttható segítségével számított kapcsolat megbízhatósága rpb, a kritérium segítségével is meghatározható χ 2 a szabadságfokok száma df= 2.
Pont-biszerial korreláció
A nyomatékok szorzatának korrelációs együtthatójának utólagos módosulását a pontozott biszéria tükrözte r. Ez a stat. két változó kapcsolatát mutatja, amelyek közül az egyik állítólag folytonos és normális eloszlású, míg a másik a szó pontos értelmében diszkrét. A pont-biszerial korrelációs együtthatót jelöljük r pbis Mert be r pbis a dichotómia a diszkrét változó valódi természetét tükrözi, és nem mesterséges, mint ebben az esetben r bis, előjele önkényesen van meghatározva. Ezért minden gyakorlathoz célokat r pbis 0,00 és +1,00 közötti tartományban veszik figyelembe.
Van olyan eset is, amikor két változót folytonosnak és normális eloszlásúnak tekintünk, de mindkettőt mesterségesen dichotomizáljuk, mint a biserial korreláció esetében. Az ilyen változók közötti kapcsolat értékelésére a tetrachor korrelációs együtthatót használjuk r tet, amelyet szintén Pearson tenyésztett ki. Fő (pontos) képletek és számítási eljárások r tet meglehetősen összetettek. Ezért gyakorlással. ez a módszer a közelítéseket használja r tet rövidített eljárások és táblázatok alapján nyert.
/online/dictionary/dictionary.php?term=511
PONTOS BISERIÁLIS KORRELÁCIÓS EGYÜTTHATÓ a korrelációs együttható két változó között, amelyek közül az egyiket egy dichotóm skálán, a másikat egy intervallumskálán mérik. A klasszikus és a modern tesztológiában a tesztfeladat minőségének mutatójaként használják - a megbízhatóság-konzisztencia az általános tesztpontszámmal.
A mért változók korrelálásához dichotóm és intervallum skála használat pont-biszerial korrelációs együttható.
A pont-biszerial korrelációs együttható a változók arányának korrelációs elemzésének módszere, amelyek közül az egyiket a névskálán mérik, és csak 2 értéket vesz fel (például férfiak / nők, a válasz helyes / a válasz hibás, van előjel / nincs előjel), a második pedig a skálaarányokban vagy intervallumskálában. A pont-biszerial korrelációs együttható kiszámításának képlete:

Ahol:
m1 és m0 X átlagos értéke 1 vagy 0 Y-ban.
σx az X összes értékének szórása
n1 ,n0 – X értékek száma 1-től vagy 0-tól Y-ig.
n az értékpárok teljes száma
Leggyakrabban ezt a típusú korrelációs együtthatót használják a tesztelemek kapcsolatának kiszámítására egy összegző skálával. Ez az érvényesítési ellenőrzés egyik típusa.
39. Rang-biszerial korrelációs együttható.
A korrelációról általában lásd a 36. kérdést Val vel. 56 (64) 063.JPG
harchenko-korranaliz.pdf p. 28
A rang-biszerial korrelációs együttható, amelyet akkor használunk, ha az egyik változó ( x) sorrendi léptékben jelenik meg, a másik pedig ( Y) - dichotóm, képlettel számítva
. 
Itt látható az egységben lévő objektumok átlagos rangja Y; a nullával rendelkező objektumok átlagos rangja Y, n a minta mérete.
Vizsgálat szignifikancia hipotézisek A rang-biszerial korrelációs együtthatót a pont-biszerial korrelációs együtthatóhoz hasonlóan hajtjuk végre Student-féle t-próbával a képletekben való helyettesítéssel rpb a rrb.
Amikor egy változót egy dichotóm skálán mérünk (változó x), a másik pedig a rangskálán (Y változó), a rang-biszerial korrelációs együttható használatával. Emlékszünk, hogy a változó x, dichotóm skálán mérve csak két értéket (kódot) vesz fel, 0 és 1. Külön hangsúlyozzuk, hogy annak ellenére, hogy ez az együttható –1 és +1 tartományban változik, előjele nem számít az értelmezés szempontjából eredmények. Ez egy újabb kivétel az általános szabály alól.
Ennek az együtthatónak a kiszámítása a következő képlet szerint történik:
ahol ` x 1– átlagos rangot a változó elemeihez képest Y, amely a változóban szereplő 1. kódnak (jellemzőnek) felel meg x;
„X 0 – a változó azon elemeinek átlagos rangja Y, amely a változóban szereplő 0 kódnak (jellemzőnek) felel meg X\
N- a változó elemeinek teljes száma x.
A rang-biszerial korrelációs együttható alkalmazásához a következő feltételeknek kell teljesülniük:
1. Az összehasonlítandó változókat különböző skálákon kell mérni: egy X- dichotóm léptékben; egy másik Y- a rangsorolási skálán.
2. A változó jellemzők száma az összehasonlított változókban xés Y azonosnak kell lennie.
3. A rang-biszerial korrelációs együttható megbízhatósági szintjének felméréséhez a (11.9) képletet és a kritikus értékek táblázatát kell használni a Student-teszthez, amikor k = n-2.
http://psystat.at.ua/publ/drugie_vidy_koehfficienta_korreljacii/1-1-0-38
Azok az esetek, amikor a változók egyike jelen van dichotóm skála, a másik pedig be rang (sorrend), használatát igénylik rang-biszerial korrelációs együttható:
rpb = 2 / n * (m1 - m0)
ahol:
n a mérési objektumok száma
m1 és m0 - a második változóban 1 vagy 0 értékű objektumok átlagos rangja.
Ezt az együtthatót használják a tesztek érvényességének ellenőrzésekor is.
40. Lineáris korrelációs együttható.
A korrelációról általában (és különösen a lineáris korrelációról) lásd a 36. kérdést Val vel. 56 (64) 063.JPG
Mr. PEARSON KORRELÁCIÓS EGYÜTTMŰKÖDŐ
r- Pearson (Pearson r) két metrika közötti kapcsolat tanulmányozására szolgálmás, ugyanazon a mintán mért változók. Sok olyan helyzet van, amikor célszerű használni. Befolyásolja-e az intelligencia a felsőbb éves egyetemi évek teljesítményét? A munkavállaló fizetésének nagysága összefügg a kollégákkal szembeni jóindulatával? Befolyásolja-e a tanuló hangulata egy összetett számtani feladat megoldásának sikerét? Az ilyen kérdések megválaszolásához a kutatónak két, a minta minden tagját érdeklő mutatót kell mérnie. A kapcsolat tanulmányozásához szükséges adatokat az alábbi példa szerint táblázatba foglaljuk.
6.1. PÉLDA
A táblázat egy példát mutat be az intelligencia két mutatójának (verbális és non-verbális) kezdeti mérési adataira 20 8. osztályos tanulónál.

A változók közötti kapcsolat egy szórásdiagram segítségével ábrázolható (lásd 6.3. ábra). A diagramon látható, hogy a mért mutatók között van némi kapcsolat: minél nagyobb a verbális intelligencia értéke, annál (főleg) annál nagyobb a non-verbális intelligencia.
Mielőtt megadnánk a korrelációs együttható képletét, a 6.1. példa adatai alapján próbáljuk meg nyomon követni előfordulásának logikáját. Az egyes /-pontok (a / számú alany) helyzete a szórási diagramon a többi ponthoz képest (6.3. ábra) a változók megfelelő értékeinek a változóktól való eltérésének nagyságával és előjelével adható meg. átlagos értékek: (xj - MJ és (ész nál nél ). Ha ezeknek az eltéréseknek a jelei egybeesnek, akkor ez a pozitív kapcsolat javára utal (nagy értékek a x nagy értékeknek felelnek meg nál nél vagy kisebb értékeket x kisebb értékeknek felel meg y).
Az 1. számú tantárgynál az átlagtól való eltérés xés által nál nél pozitív, a 3. számú alany esetében pedig mindkét eltérés negatív. Mindkettő adatai tehát pozitív kapcsolatot jeleznek a vizsgált tulajdonságok között. Éppen ellenkezőleg, ha az átlagtól való eltérések jelei xés által nál nél eltérő, ez negatív kapcsolatot jelez a jelek között. Így a 4. tantárgynál az átlagtól való eltérés x szerint negatív y - pozitív, a 9. tantárgy esetében pedig fordítva.
Így ha az eltérések szorzata (x, - M x ) x (ész nál nél ) pozitív, akkor a /-alany adatai közvetlen (pozitív) összefüggést jeleznek, ha pedig negatív, akkor fordított (negatív) kapcsolatot. Ennek megfelelően, ha xwy többnyire egyenesen arányosak, akkor az eltérések szorzatainak nagy része pozitív lesz, ha pedig fordítottan kapcsolódnak egymáshoz, akkor a szorzatok többsége negatív lesz. Ezért az adott mintára vonatkozó eltérések összes szorzatának összege általános mutatóként szolgálhat a kapcsolat erősségére és irányára:
A változók közötti egyenesen arányos kapcsolat esetén ez az érték nagy és pozitív - a legtöbb alanynál az eltérések előjelben egybeesnek (az egyik változó nagy értékei a másik változó nagy értékeinek felelnek meg, és fordítva). Ha xés nál nél visszajelzése van, akkor a legtöbb alanynál az egyik változó nagy értékei egy másik változó kisebb értékeinek felelnek meg, azaz a szorzatok előjelei negatívak lesznek, és a termékek egészének összege is nagy lesz abszolút értékben, de negatív előjelben. Ha nincs szisztematikus kapcsolat a változók között, akkor a pozitív tagok (az eltérések szorzatai) negatív tagokkal lesznek kiegyenlítve, és az eltérések összes szorzatának összege nullához közelít.
Hogy a termékek összege ne függjön a minta nagyságától, elegendő azt átlagolni. De minket a kapcsolat mértéke nem általános paraméterként érdekel, hanem annak számított becsléseként - statisztika. Ezért, ami a diszperziós képletet illeti, ebben az esetben ugyanezt tesszük, az eltérések szorzatainak összegét nem osztjuk el N, és a TV-ben - 1. Kiderül, hogy a fizikában és a műszaki tudományokban széles körben használt kommunikációs mérőszám, amelyet ún. kovariancia (Kovahance):

NÁL NÉL
 a pszichológiában a fizikával ellentétben a legtöbb változót tetszőleges skálákon mérik, mivel a pszichológusokat nem az attribútum abszolút értéke érdekli, hanem az alanyok relatív helyzete a csoportban. Ezenkívül a kovariancia nagyon érzékeny arra a skálára (szórásra), amelyben a jellemzőket mérik. Ahhoz, hogy a kommunikáció mértéke független legyen bármelyik attribútum mértékegységeitől, elegendő a kovariancia felosztása a megfelelő szórásokra. Így megszerezték for-K. Pearson-féle korrelációs együttható öszvér:
a pszichológiában a fizikával ellentétben a legtöbb változót tetszőleges skálákon mérik, mivel a pszichológusokat nem az attribútum abszolút értéke érdekli, hanem az alanyok relatív helyzete a csoportban. Ezenkívül a kovariancia nagyon érzékeny arra a skálára (szórásra), amelyben a jellemzőket mérik. Ahhoz, hogy a kommunikáció mértéke független legyen bármelyik attribútum mértékegységeitől, elegendő a kovariancia felosztása a megfelelő szórásokra. Így megszerezték for-K. Pearson-féle korrelációs együttható öszvér:vagy az o x és kifejezések behelyettesítése után

Ha mindkét változó értékét a képlet segítségével r-értékekre konvertálták

akkor az r-Pearson korrelációs együttható képlete egyszerűbbnek tűnik (071.JPG):
/dict/sociology/article/soc/soc-0525.htm
LINEÁRIS KORRELÁCIÓ- statisztikai, nem oksági lineáris kapcsolat két mennyiségi változó között xés nál nél. A "K.L. tényező" segítségével mérve. Pearson, ami a kovariancia elosztásának eredménye mindkét változó szórásával:
![]() ,
,
ahol s xy- kovariancia a változók között xés nál nél;
s x , s y- a változók szórása xés nál nél;
x én , y én- változó értékek xés nál nél objektumszámhoz én;
x, y- a változók számtani átlagai xés nál nél.
Pearson-féle arány rértékeket vehet fel az intervallumból [-1; +1]. Jelentése r = 0 azt jelenti, hogy a változók között nincs lineáris kapcsolat xés nál nél(de nem zárja ki a nemlineáris statisztikai összefüggést). Pozitív együttható értékek ( r> 0) közvetlen lineáris összefüggést jelez; minél közelebb van értéke a +1-hez, annál erősebb a statisztikai közvetlen kapcsolat. Negatív együttható értékek ( r < 0) свидетельствуют об обратной линейной связи; чем ближе его значение к -1, тем сильнее обратная связь. Значения r= ±1 teljes lineáris kapcsolat meglétét jelenti, közvetlen vagy fordított. Teljes kapcsolat esetén minden pont koordinátákkal ( x én , y én) feküdjön egy egyenesen y = a + bx.
"K.L. együttható." Pearsont a kapcsolat szorosságának mérésére is használják a lineáris páros regressziós modellben.
41. Korrelációs mátrix és korrelációs gráf.
A korrelációról általában lásd a 36. kérdést Val vel. 56 (64) 063.JPG
korrelációs mátrix. A korrelációelemzés gyakran nem két, hanem egy mintán kvantitatív skálán mért sok változó kapcsolatának vizsgálatát foglalja magában. Ebben az esetben ennek a változókészletnek minden párjára korrelációkat számítanak ki. A számításokat általában számítógépen végzik, és az eredmény egy korrelációs mátrix.
Korrelációs mátrix(korreláció mátrix) a halmaz minden párjára vonatkozó azonos típusú korrelációk kiszámításának eredménye R egy mintán kvantitatív skálán mért változók.
PÉLDA
Tegyük fel, hogy 5 változó közötti kapcsolatokat vizsgálunk (vl, v2,..., v5; P= 5), mintán mérve N=30 emberi. Az alábbiakban a kiindulási adatok táblázata és a korrelációs mátrix látható.
És  kapcsolódó adatok:
kapcsolódó adatok:
 Korrelációs mátrix:
Korrelációs mátrix:
Könnyen belátható, hogy a korrelációs mátrix négyzet alakú, szimmetrikus a főátlóhoz képest (takkakg, y = /) y, egységekkel a főátlón (hiszen G és = Gu = 1).
A korrelációs mátrix az négyzet: a sorok és oszlopok száma megegyezik a változók számával. Ő az szimmetrikus a főátlóhoz képest, mivel a korreláció x Val vel nál nél egyenlő a korrelációval nál nél Val vel X. Az egységek a főátlóján helyezkednek el, mivel egy jellemző korrelációja önmagával egyenlő eggyel. Következésképpen a korrelációs mátrix nem minden elemét vizsgáljuk, hanem azokat, amelyek a főátló felett vagy alatt vannak.
a korrelációs együtthatók száma, Az összefüggések vizsgálata során elemzendő P jellemzőket a következő képlet határozza meg: P(P- 1)/2. A fenti példában az ilyen korrelációs együtthatók száma 5(5 - 1)/2 = 10.
A korrelációs mátrix elemzésének fő feladata az jellemzők halmazának összefüggéseinek szerkezetét feltárva. Ez vizuális elemzést tesz lehetővé korrelációs plejádok- grafikus kép szerkezetek statisztikailagjelentős kapcsolatokat ha nincs nagyon sok ilyen kapcsolat (akár 10-15). Egy másik lehetőség a többváltozós módszerek alkalmazása: többszörös regressziós, faktoriális vagy klaszteranalízis (lásd a "Többváltozós módszerek..." részt). Faktorális vagy klaszteranalízis segítségével olyan változók csoportosítását lehet azonosítani, amelyek szorosabban kapcsolódnak egymáshoz, mint más változókhoz. Ezeknek a módszereknek a kombinációja is nagyon hatásos, például ha sok jel van, és nem homogének.
Az összefüggések összehasonlítása - egy további feladat a korrelációs mátrix elemzése, amelynek két lehetősége van. Ha a korrelációs mátrix valamelyik sorában (az egyik változónál) összefüggéseket kell összehasonlítani, akkor a függő minták összehasonlítási módszerét alkalmazzuk (148-149. oldal). A különböző mintákra számított azonos nevű összefüggések összehasonlításakor a független minták összehasonlítási módszerét alkalmazzuk (147-148. o.).
Összehasonlítási módszerekösszefüggések átlókban korrelációs mátrix (véletlenszerű folyamat stacionaritásának felmérésére) és összehasonlítása számos A különböző mintákhoz (homogenitásuk miatt) kapott korrelációs mátrixok időigényesek, és túlmutatnak e könyv keretein. Ezekkel a módszerekkel GV Sukhodolsky 1 című könyvéből ismerkedhet meg.
Az összefüggések statisztikai szignifikancia problémája. A probléma az, hogy a statisztikai hipotézisvizsgálati eljárás magában foglalja egy-többszörös egy mintán végzett vizsgálat. Ha ugyanazt a módszert alkalmazzuk sokszor, még ha különböző változókhoz viszonyítva is, akkor a pusztán véletlenül eredmény elérésének valószínűsége nő. Általában, ha megismételjük ugyanazt a hipotézisvizsgálati módszert időkre különböző változókra vagy mintákra vonatkozóan, akkor a megállapított a érték mellett garantáltan megkapjuk a hipotézis megerősítését. áh az esetek száma.
Tegyük fel, hogy a 15 változóra vonatkozó korrelációs mátrixot elemezzük, azaz 15(15-1)/2 = 105 korrelációs együtthatót számolunk. A hipotézisek teszteléséhez az a = 0,05 szintet állítjuk be, a hipotézis 105-szöri tesztelésével ötször (!) kapunk megerősítést, függetlenül attól, hogy a kapcsolat valóban létezik-e. Ennek ismeretében és mondjuk 15 "statisztikailag szignifikáns" korrelációs együttható beszerzése után meg tudjuk-e mondani, hogy ezek közül melyiket kaptuk véletlenül, és melyek tükröznek valós kapcsolatot?
Szigorúan véve a statisztikai döntés meghozatalához az a szintet annyiszorosára kell csökkenteni, ahány hipotézis van tesztelve. Ez azonban aligha tanácsos, mivel egy valóban létező kapcsolat figyelmen kívül hagyásának (II. típusú hiba) valószínűsége megjósolhatatlanul megnő.
A korrelációs mátrix önmagában nem elegendő alapa benne foglalt egyes együtthatók statisztikai következtetéseihezösszefüggések!
A probléma megoldásának egyetlen igazán meggyőző módja van: a mintát véletlenszerűen két részre osztjuk, és csak azokat az összefüggéseket vesszük figyelembe, amelyek a minta mindkét részében statisztikailag szignifikánsak. Alternatív megoldás lehet többváltozós módszerek (faktoriális, klaszter- vagy többszörös regressziós analízis) alkalmazása – statisztikailag szignifikánsan összefüggő változók csoportjainak kiválasztására és utólagos értelmezésére.
A hiányzó értékek problémája. Ha az adatokban hiányzó értékek vannak, akkor a korrelációs mátrix kiszámítására két lehetőség van: a) az értékek soronkénti törlése (kizárnieseteklistaszerűen); b) értékek páronkénti törlése (kizárniesetekpáronként). Nál nél soronkénti törlés hézagokkal rendelkező megfigyelések esetén a teljes sor törlésre kerül annak az objektumnak (alanynak), amelynek az egyik változóhoz legalább egy értéke hiányzik. Ez a módszer "helyes" korrelációs mátrixhoz vezet abban az értelemben, hogy az összes együtthatót ugyanabból az objektumkészletből számítják ki. Ha azonban a hiányzó értékek véletlenszerűen vannak elosztva a változókban, akkor ez a módszer oda vezethet, hogy a vizsgált adatkészletben egyetlen objektum sem marad (minden sor tartalmazni fog legalább egy hiányzó értéket). A helyzet elkerülése érdekében használjon egy másik módszert, az úgynevezett páronkénti eltávolítás. Ez a módszer csak az egyes kiválasztott változóoszloppárok hiányosságait veszi figyelembe, és figyelmen kívül hagyja a többi változóban lévő hiányosságokat. A változópárra vonatkozó korrelációt azokra az objektumokra számítjuk ki, ahol nincs hézag. Sok esetben, különösen, ha a rések száma viszonylag kicsi, mondjuk 10%, és a rések meglehetősen véletlenszerűen vannak elosztva, ez a módszer nem vezet komoly hibákhoz. Néha azonban nem ez a helyzet. Például a becslés szisztematikus torzításában (eltolódásában) a hézagok szisztematikus elhelyezkedése "elrejthető", ez az oka a különböző részhalmazokra épített korrelációs együtthatók eltérésének (például az objektumok különböző alcsoportjaira). ). Egy másik probléma, amely a -val számított korrelációs mátrixszal kapcsolatos párban A rés eltávolítása akkor következik be, ha ezt a mátrixot más típusú elemzésekben (például többszörös regressziós vagy faktoranalízisben) használják. Feltételezik, hogy egy "helyes" korrelációs mátrixot használnak bizonyos szintű konzisztenciával és a különböző együtthatók "megfelelésével". A "rossz" (elfogult) becslésű mátrix használata azt a tényt eredményezi, hogy a program vagy nem tud elemezni egy ilyen mátrixot, vagy az eredmények hibásak lesznek. Ezért, ha páronkénti módszert alkalmazunk a hiányzó adatok kiküszöbölésére, akkor ellenőrizni kell, hogy vannak-e szisztematikus minták a hiányosságok eloszlásában.
Ha a hiányzó adatok páronkénti kiküszöbölése nem vezet szisztematikus eltolódáshoz az átlagokban és szórásokban (szórásokban), akkor ezek a statisztikák hasonlóak lesznek a hiányosságok megszüntetésének soronkénti módszerével számítottakhoz. Ha szignifikáns eltérés van, akkor okkal feltételezhető, hogy a becslésekben eltolódás van. Például, ha a változó értékeinek átlaga (vagy szórása). DE, amelyet a változóval való korrelációjának kiszámításakor használtak NÁL NÉL, sokkal kisebb, mint a változó azonos értékeinek átlaga (vagy szórása). DE, amelyeket a C változóval való korrelációjának kiszámításához használtunk, akkor minden okkal feltételezhető, hogy ez a két korreláció (A-Bminket) az adatok különböző részhalmazai alapján. A korrelációkban eltolódás következik be, amelyet a változók értékei közötti rések nem véletlenszerű elhelyezkedése okoz.
Korrelációs plejádok elemzése. A korrelációs mátrix elemeinek statisztikai szignifikancia problémájának megoldása után a statisztikailag szignifikáns összefüggések grafikusan ábrázolhatók korrelációs plejád vagy plejádok formájában. Korrelációs galaxis - csúcsokból és az őket összekötő egyenesekből álló alakzat. A csúcsok megfelelnek a jellemzőknek, és általában számokkal jelölik - a változók számaival. A vonalak statisztikailag szignifikáns összefüggéseknek felelnek meg, és grafikusan fejezik ki a kapcsolat előjelét, esetenként a /j-szignifikancia szintjét.
A korrelációs galaxis képes tükrözni összes a korrelációs mátrix statisztikailag szignifikáns összefüggései (néha ún korrelációs grafikon ) vagy csak azok értelmesen kiválasztott részét (például a faktoranalízis eredménye szerint egy faktornak megfelelő).
PÉLDA EGY KORRELÁCIÓS PLEIADI KÉPZÉSÉRE

Felkészülés a végzettek állami (végső) minősítésére: USE adatbázis kialakítása (az összes kategória USE résztvevőinek általános listája, tantárgyak megjelölésével) - a tantárgyak egybeesése esetén tartaléknapok figyelembevétele;
Munkaterv (27)
Megoldás2. Az oktatási intézmény tevékenységei a természeti és matematikai nevelés tantárgyak tartalmának javítására és minőségértékelésére MOU 4. számú középiskola, Litvinovskaya, Chapaevskaya,
A korrelációelemzés egy olyan módszer, amely lehetővé teszi bizonyos számú valószínűségi változó közötti kapcsolatok kimutatását. A korrelációelemzés célja, hogy becslést adjon az egyes valós folyamatokat jellemző valószínűségi változók vagy jellemzők közötti kapcsolatok erősségére.
Ma azt javasoljuk, hogy vizsgáljuk meg, hogyan használják Spearman korrelációs elemzését a kommunikációs formák vizuális megjelenítésére a gyakorlati kereskedésben.
Spearman korreláció vagy a korrelációelemzés alapja
Ahhoz, hogy megértsük, mi a korrelációelemzés, először meg kell értenünk a korreláció fogalmát.
Ugyanakkor, ha az árfolyam elkezd a kívánt irányba mozogni, időben fel kell oldani a pozíciókat.
Ehhez a korrelációs elemzésen alapuló stratégiához a magas korrelációs fokú kereskedési eszközök a legalkalmasabbak (EUR/USD és GBP/USD, EUR/AUD és EUR/NZD, AUD/USD és NZD/USD, CFD szerződések, stb.) .
Videó: A Spearman-korreláció alkalmazása a Forex piacon

A gyakorlatban a Spearman-féle rangkorrelációs együtthatót (P) gyakran használják két jellemző közötti kapcsolat szorosságának meghatározására. Az egyes jellemzők értékeit növekvő sorrendben (1-től n-ig) rangsoroljuk, majd meghatározzuk az egy megfigyelésnek megfelelő rangok közötti különbséget (d).
1. példa. Az ipari termelés volumene és az állótőke-befektetések közötti kapcsolatot az Orosz Föderáció egyik szövetségi körzetének 10 régiójában 2003-ban a következő adatok jellemzik.
Kiszámítja Spearman-féle rangkorrelációs együtthatókés Kendala. Ellenőrizze szignifikanciájukat α=0,05-nél. Fogalmazzon meg következtetést az ipari termelés volumene és az állóeszköz-befektetések közötti kapcsolatról az Orosz Föderáció vizsgált régióiban.
Rendeljen rangokat az Y jellemzőhöz és az X tényezőhöz. Határozzuk meg a d 2 négyzetek különbségének összegét!
A számológép segítségével kiszámítjuk a Spearman-féle rangkorrelációs együtthatót:
| x | Y | rang X, dx | Y, d y | (dx - dy) 2 |
| 1.3 | 300 | 1 | 2 | 1 |
| 1.8 | 1335 | 2 | 12 | 100 |
| 2.4 | 250 | 3 | 1 | 4 |
| 3.4 | 946 | 4 | 8 | 16 |
| 4.8 | 670 | 5 | 7 | 4 |
| 5.1 | 400 | 6 | 4 | 4 |
| 6.3 | 380 | 7 | 3 | 16 |
| 7.5 | 450 | 8 | 5 | 9 |
| 7.8 | 500 | 9 | 6 | 9 |
| 17.5 | 1582 | 10 | 16 | 36 |
| 18.3 | 1216 | 11 | 9 | 4 |
| 22.5 | 1435 | 12 | 14 | 4 |
| 24.9 | 1445 | 13 | 15 | 4 |
| 25.8 | 1820 | 14 | 19 | 25 |
| 28.5 | 1246 | 15 | 10 | 25 |
| 33.4 | 1435 | 16 | 14 | 4 |
| 42.4 | 1800 | 17 | 18 | 1 |
| 45 | 1360 | 18 | 13 | 25 |
| 50.4 | 1256 | 19 | 11 | 64 |
| 54.8 | 1700 | 20 | 17 | 9 |
| 364 |
Az Y jellemző X faktora közötti kapcsolat erős és közvetlen.
Spearman rangkorrelációs együtthatójának becslése
A Tanuló táblázata szerint Ttáblát találunk.
T táblázat \u003d (18; 0,05) \u003d 1,734
Mivel Tobs > Ttabl, elvetjük azt a hipotézist, hogy a rangkorrelációs együttható nullával egyenlő. Más szóval, a Spearman-féle rangkorrelációs együttható statisztikailag szignifikáns.
A rangkorrelációs együttható intervallumbecslése (konfidenciaintervallum)

Megbízhatósági intervallum Spearman rangkorrelációs együtthatójához: p(0,5431;0,9095).
2. példa. Kezdeti adatok.
| 5 | 4 |
| 3 | 4 |
| 1 | 3 |
| 3 | 1 |
| 6 | 6 |
| 2 | 2 |
| Új rangok | ||
| 1 | 1 | 1 |
| 2 | 2 | 2 |
| 3 | 3 | 3.5 |
| 4 | 3 | 3.5 |
| 5 | 5 | 5 |
| 6 | 6 | 6 |
| Ülésszámok a rendezett sorban | A tényezők elhelyezkedése a szakértő értékelése szerint | Új rangok |
| 1 | 1 | 1 |
| 2 | 2 | 2 |
| 3 | 3 | 3 |
| 4 | 4 | 4.5 |
| 5 | 4 | 4.5 |
| 6 | 6 | 6 |
| rang X, dx | Y, d y | (dx - dy) 2 |
| 5 | 4.5 | 0.25 |
| 3.5 | 4.5 | 1 |
| 1 | 3 | 4 |
| 3.5 | 1 | 6.25 |
| 6 | 6 | 0 |
| 2 | 2 | 0 |
| 21 | 21 | 11.5 |
ahol
j - linkek száma az x jellemzőhöz;
És j az azonos rangok száma a j-edik kötegben x-ben;
k - tárcsák száma az y jellemzőhöz;
K-ban - az azonos rangok száma a k-ik kötegben y-ban.
A = [(2 3 -2)]/12 = 0,5
B = [(2 3 -2)]/12 = 0,5
D = A + B = 0,5 + 0,5 = 1
Az Y jellemző és az X faktor közötti kapcsolat mérsékelt és közvetlen.
A Spearman-féle rangkorrelációs módszer lehetővé teszi két jellemző vagy a jellemzők két profilja (hierarchiája) közötti korreláció szorosságának (erősségének) és irányának meghatározását.
A rangkorreláció kiszámításához két értéksorra van szükség,
amelyek rangsorolhatók. Ezek az értéktartományok a következők lehetnek:
1) két jel ugyanabban a csoportban mérve;
2) a tulajdonságok két egyéni hierarchiája, amelyeket két alanyban azonosítottak ugyanarra a tulajdonságcsoportra vonatkozóan;
3) a jellemzők két csoportos hierarchiája,
4) a jellemzők egyéni és csoportos hierarchiája.
Először is, a mutatók külön-külön vannak rangsorolva az egyes funkciókhoz.
Általános szabály, hogy egy jellemző alacsonyabb értéke alacsonyabb rangot kap.
Az első esetben (két jellemző) rangsorolják az első jellemző egyedi értékeit, amelyeket különböző alanyok kaptak, majd a második jellemző egyedi értékeit.
Ha két attribútum pozitívan kapcsolódik egymáshoz, akkor az egyikben alacsony besorolású alanyok a másikban alacsony, a magas rangú alanyok pedig
az egyik tulajdonság a másik tulajdonságon is magas rangot kap. Az rs kiszámításához mindkét alapon meg kell határozni az adott alany által elért rangok (d) különbségét. Ezután ezeket a d mutatókat egy bizonyos módon átalakítjuk, és kivonjuk 1-ből
minél kisebb a különbség a rangok között, annál nagyobb lesz az rs, annál közelebb lesz a +1-hez.
Ha nincs összefüggés, akkor minden rang vegyes lesz, és nem lesz
nem egyezik. A képlet úgy van megtervezve, hogy ebben az esetben rs közel legyen a 0-hoz.
Negatív korreláció esetén az alanyok alacsony rangja egy tulajdonságon
egy másik attribútumban magas rangoknak felel meg, és fordítva. Minél nagyobb az eltérés az alanyok rangsorai között két változónál, annál közelebb van az rs a -1-hez.
A második esetben (két egyéni profil), egyéni
a 2 alany mindegyike által egy bizonyos (mindkettőjüknél azonos) jellemzőkészlet szerint kapott értékek. Az első rangú a legalacsonyabb értékű tulajdonságot kapja; a második rang magasabb értékű jellemző, és így tovább. Nyilvánvalóan minden jellemzőt ugyanabban a mértékegységben kell mérni, különben a rangsorolás lehetetlen. Például lehetetlen a mutatókat a Cattell személyiségkérdőív (16PF) szerint rangsorolni, ha "nyers" pontszámban vannak kifejezve, mivel a különböző tényezők értéktartománya eltérő: 0-tól 13-ig, 0-ig
20 és 0-tól 26-ig. Nem tudjuk megmondani, hogy a tényezők közül melyik lesz az első hely a súlyosság szempontjából, amíg az összes értéket egyetlen skálára nem hozzuk (leggyakrabban ez a fali skála).
Ha két tantárgy egyéni hierarchiája pozitívan kapcsolódik egymáshoz, akkor azok a tulajdonságok, amelyek az egyiknél alacsony rangúak, a másiknál alacsonyabbak lesznek, és fordítva. Például, ha az egyik alanynál az E faktor (dominancia) a legalacsonyabb rangú, akkor egy másik alanynál alacsony rangúnak kell lennie, ha az egyik alany rendelkezik C faktorral.
(érzelmi stabilitás) rendelkezik a legmagasabb ranggal, akkor a másik alanynak is rendelkeznie kell
ennek a tényezőnek magas a rangja stb.
A harmadik esetben (két csoportprofil) az alanyok 2 csoportjában kapott átlagos csoportértékeket egy bizonyos jellemzőkészlet szerint rangsorolják, amely két csoport esetében azonos. A következőkben a gondolatmenet ugyanaz, mint az előző két esetben.
A 4. (egyéni és csoportos profilok) esetében az alany egyéni értékeit és a csoport átlagértékeit külön-külön rangsorolják, ugyanazon jellemzőkészlet szerint, amelyet általában ennek az egyénnek a kizárásával kapunk. alany - nem vesz részt az átlagos csoportprofilban, amellyel összehasonlítják. A rangkorreláció segítségével ellenőrizheti, mennyire konzisztensek az egyéni és csoportprofilok.
Mind a négy esetben a kapott korrelációs együttható szignifikanciáját az N rangsorolt értékek száma határozza meg. Az első esetben ez a szám egybeesik az n mintamérettel. A második esetben a megfigyelések száma a hierarchiát alkotó jellemzők száma lesz. A harmadik és negyedik esetben N az összehasonlított jellemzők száma is, és nem a csoportokban lévő alanyok száma. A részletes magyarázatok a példákban találhatók. Ha az rs abszolút értéke elér vagy meghalad egy kritikus értéket, a korreláció szignifikáns.
Hipotézisek.
Két hipotézis lehetséges. Az első az 1. esetre vonatkozik, a második a másik három esetre.
A hipotézisek első változata
H0: Az A és B változók közötti korreláció nem különbözik nullától.
H1: Az A és B változók közötti korreláció szignifikánsan különbözik a nullától.
A hipotézisek második változata
H0: Az A és B hierarchia közötti korreláció nem különbözik a nullától.
H1: Az A és B hierarchia közötti korreláció jelentősen eltér a nullától.
A rangkorrelációs együttható korlátai
1. Változónként legalább 5 észrevételt kell benyújtani. A minta felső határát a rendelkezésre álló kritikus értékek táblázatai határozzák meg.
2. Az rs Spearman-féle rangkorrelációs együttható nagyszámú azonos ranggal az egyik vagy mindkét összehasonlított változóra elnagyolt értékeket ad. Ideális esetben mindkét korrelált sorozatnak két egymáshoz nem illő értéksorozatnak kell lennie. Ha ez a feltétel nem teljesül, akkor ugyanazon besorolási fokozatok tekintetében kiigazítást kell végezni.
A Spearman-féle rangkorrelációs együttható a következő képlettel számítható ki:
Ha mindkét összehasonlított rangsorban azonos rangú csoportok vannak, akkor a rangkorrelációs együttható kiszámítása előtt ugyanazon Ta és Tv rangoknál korrekciókat kell végezni:
Ta \u003d Σ (a3 - a) / 12,
TV \u003d Σ (v3 - c) / 12,
ahol a az A rangsor minden azonos rangú csoportjának térfogata, c pedig mindegyik térfogata
egyenlő rangú csoportok a B rangsorban.
Az rs tapasztalati értékének kiszámításához használja a következő képletet:
 Spearman-féle rangkorrelációs együttható rs kiszámítása
Spearman-féle rangkorrelációs együttható rs kiszámítása
1. Határozza meg, hogy melyik két jellemzőben vagy két jellemző hierarchiában vesz részt
összehasonlítása A és B változókkal.
2. Rangsorolja az A változó értékeit, a legkisebb értékhez az 1-es rangot rendelve a rangsorolási szabályok szerint (lásd A.2.3). Írja be a rangsorokat a táblázat első oszlopába az alanyok vagy jelek száma szerinti sorrendben.
3. Rendezze el a B változó értékeit, ugyanazon szabályok szerint. Írja be a rangsorokat a táblázat második oszlopába az alanyok vagy jelek száma szerinti sorrendben.
5. Négyzetre emelje az egyes különbségeket: d2. Írja be ezeket az értékeket a táblázat negyedik oszlopába.
Ta \u003d Σ (a3 - a) / 12,
TV \u003d Σ (v3 - c) / 12,
ahol a az A rangsorban lévő azonos rangú csoportok térfogata; c - az egyes csoportok térfogata
ugyanez a helyezés a B rangsorban.
a) azonos rangok hiányában
rs 1 − 6 ⋅
b) azonos rendfokozatúak jelenlétében
Σd 2 T T
r 1 − 6 ⋅ a hüvelyk,
ahol Σd2 a rangok közötti különbségek négyzetes összege; A Ta és a TV ugyanennek a javítása
N a rangsorolásban részt vevő tantárgyak vagy jellemzők száma.
9. Határozza meg a táblázatból (lásd a 4.3. függeléket) az rs kritikus értékeit egy adott N-hez. Ha rs nagyobb, vagy legalább egyenlő a kritikus értékkel, akkor a korreláció jelentősen eltér 0-tól.
4.1 példa Az alkoholfogyasztás reakciója szemmotoros reakciótól való függésének mértékének meghatározásakor a vizsgálati csoportban adatokat kaptunk alkoholfogyasztás előtt és ivás után. Függ-e az alany reakciója a mérgezés állapotától?
Kísérleti eredmények:
Előtte: 16, 13, 14, 9, 10, 13, 14, 14, 18, 20, 15, 10, 9, 10, 16, 17, 18. Utána: 24, 9, 10, 23, 20, 11, 12, 19, 18, 13, 14, 12, 14, 7, 9, 14. Fogalmazzuk meg a hipotéziseket:
H0: az alkoholfogyasztás előtti és az ivás utáni reakció függésének mértéke közötti korreláció nem tér el nullától.
H1: az alkoholfogyasztás előtti és az ivás utáni reakció függésének mértéke közötti összefüggés szignifikánsan különbözik a nullától.
4.1. táblázat. A d2 számítása az rs Spearman-rang korrelációs együtthatóhoz a szemmotoros reakció paramétereinek összehasonlításakor a kísérlet előtt és után (N=17)
|
értékeket |
értékeket |
|||||
 Mivel duplikált rangjaink vannak, ebben az esetben az azonos rangokhoz igazított képletet alkalmazzuk:
Mivel duplikált rangjaink vannak, ebben az esetben az azonos rangokhoz igazított képletet alkalmazzuk:
Ta= ((23-2)+(33-3)+(23-2)+(33-3)+(23-2)+(23-2))/12=6
Tb =((23-2)+(23-2)+(33-3))/12=3
Keresse meg a Spearman-együttható tapasztalati értékét:
rs = 1-6*((767,75+6+3)/(17*(172-1)))=0,05
A táblázat szerint (4.3. melléklet) megtaláljuk a korrelációs együttható kritikus értékeit
0,48 (p ≤ 0,05)
0,62 (p ≤ 0,01)
Kapunk
rs=0,05∠rcr(0,05)=0,48
Következtetés: a H1 hipotézist elvettük, a H0-t elfogadtuk. Azok. fokozat közötti összefüggés
az alkoholfogyasztás előtti és utáni reakció függése nem különbözik a nullától.
a jelenségek közötti összefüggések statisztikai vizsgálatának kvantitatív értékelése, amelyet nem-paraméteres módszerekben alkalmaznak.![]()
A mutató megmutatja, hogy a rangok közötti különbségek négyzetes összege miben tér el a kapcsolat hiánya esetétől.
Szolgálati megbízás. Ezzel az online számológéppel a következőket teheti:
- Spearman-féle rangkorrelációs együttható kiszámítása;
- az együttható konfidenciaintervallumának kiszámítása és szignifikancia értékelése;
Spearman rangkorrelációs együtthatója a kommunikáció szorosságának értékelésének mutatóira utal. A rangkorrelációs együttható, valamint más korrelációs együtthatók kapcsolatának szorosságának kvalitatív jellemzője a Chaddock-skála segítségével értékelhető.
Együttható számítás a következő lépésekből áll:
A Spearman-féle rangkorrelációs együttható tulajdonságai
Alkalmazási terület. Rangkorrelációs együttható két halmaz közötti kommunikáció minőségének értékelésére szolgál. Ezenkívül statisztikai szignifikanciáját használják fel a heteroszkedaszticitásra vonatkozó adatok elemzésekor.
Példa. Az X és Y megfigyelt változók adatmintáján:
- rangsor táblázatot készíteni;
- keresse meg a Spearman-féle rangkorrelációs együtthatót, és tesztelje szignifikanciáját a 2a szinten
- felmérni a függőség természetét
| x | Y | rang X, dx | Y, d y |
| 28 | 21 | 1 | 1 |
| 30 | 25 | 2 | 2 |
| 36 | 29 | 4 | 3 |
| 40 | 31 | 5 | 4 |
| 30 | 32 | 3 | 5 |
| 46 | 34 | 6 | 6 |
| 56 | 35 | 8 | 7 |
| 54 | 38 | 7 | 8 |
| 60 | 39 | 10 | 9 |
| 56 | 41 | 9 | 10 |
| 60 | 42 | 11 | 11 |
| 68 | 44 | 12 | 12 |
| 70 | 46 | 13 | 13 |
| 76 | 50 | 14 | 14 |
Rang mátrix.
| rang X, dx | Y, d y | (dx - dy) 2 |
| 1 | 1 | 0 |
| 2 | 2 | 0 |
| 4 | 3 | 1 |
| 5 | 4 | 1 |
| 3 | 5 | 4 |
| 6 | 6 | 0 |
| 8 | 7 | 1 |
| 7 | 8 | 1 |
| 10 | 9 | 1 |
| 9 | 10 | 1 |
| 11 | 11 | 0 |
| 12 | 12 | 0 |
| 13 | 13 | 0 |
| 14 | 14 | 0 |
| 105 | 105 | 10 |
A mátrix összeállításának helyességének ellenőrzése az ellenőrzőösszeg számítása alapján:
A mátrix oszlopainak összege egyenlő egymással és az ellenőrző összeggel, ami azt jelenti, hogy a mátrix helyesen van összeállítva.
A képlet segítségével kiszámítjuk a Spearman-féle rangkorrelációs együtthatót.
Az Y tulajdonság és az X faktor közötti kapcsolat erős és közvetlen
A Spearman-féle rangkorrelációs együttható jelentősége
Annak érdekében, hogy a nullhipotézist α szignifikancia szinten teszteljük, az általános Spearman-rangkorrelációs együttható nullával egyenlő a H i versengő hipotézis mellett. p ≠ 0, ki kell számítani a kritikus pontot:

ahol n a minta mérete; ρ a Spearman-féle minta rangkorrelációs együtthatója: t(α, k) a kétoldali kritikus tartomány kritikus pontja, amelyet a Student-féle eloszlás kritikus pontjainak táblázatából találunk, az α szignifikanciaszint és a szabadsági fokok k = n-2.
Ha |p|< Т kp - нет оснований отвергнуть нулевую гипотезу. Ранговая корреляционная связь между качественными признаками не значима. Если |p| >T kp - a nullhipotézist elvetik. A minőségi jellemzők között jelentős rangkorreláció van.
A Student táblázata szerint t(α/2, k) = (0,1/2;12) = 1,782
Mivel T kp< ρ , то отклоняем гипотезу о равенстве 0 коэффициента ранговой корреляции Спирмена. Другими словами, коэффициент ранговой корреляции статистически - значим и ранговая корреляционная связь между оценками по двум тестам значимая.



